酷睿2的十年:一场Intel与AMD的生死博弈
距离Intel著名的64bit处理器Core 2 Duo(酷睿2)发布已经整整十年,从普及型的E6400到旗舰级的Core2 Extreme X6800,这一系列由Intel 65nm工艺打造的处理器中有太多的经典产品。可以说,酷睿2是桌面平台处理器的转折点,引用Anandtech当年的评价就是:“这是半导体有史以来最振奋人心的产品”。

酷睿2的发布大幅改变了处理器的版图,过去Netburst家族以Northwood和Prescott核心为首的Pentium4和Pentium D处理器一味飙主频的路线已经走火入魔,半导体的发展方向一再偏离效率,带来了巨大的发热和功耗问题,在90nm遇到严重瓶颈后(进入90nm工艺后,业界发现之前摩尔定律一贯的工艺提升,功耗下降的规律失灵了,prescott处理器因为发热过大无法按既定路线突破4Ghz,甚至引发了散热器大规模换代),对手AMD的Athlon 64X2处理器同时在性能和效率加冕为王。
当时的intel被迫做出重大修正,微架构上抛弃了对主频飙升有利的超长流水线设计,引入大量来自Pentium PRO和Pentium M的技术,但并不是仅仅在Yonah的微架构上增加一些新功能或者译码器那么简单(在十年前盛传酷睿2仅仅是Yonah的增强版)。是时候来回顾一下酷睿2带来的震撼了。
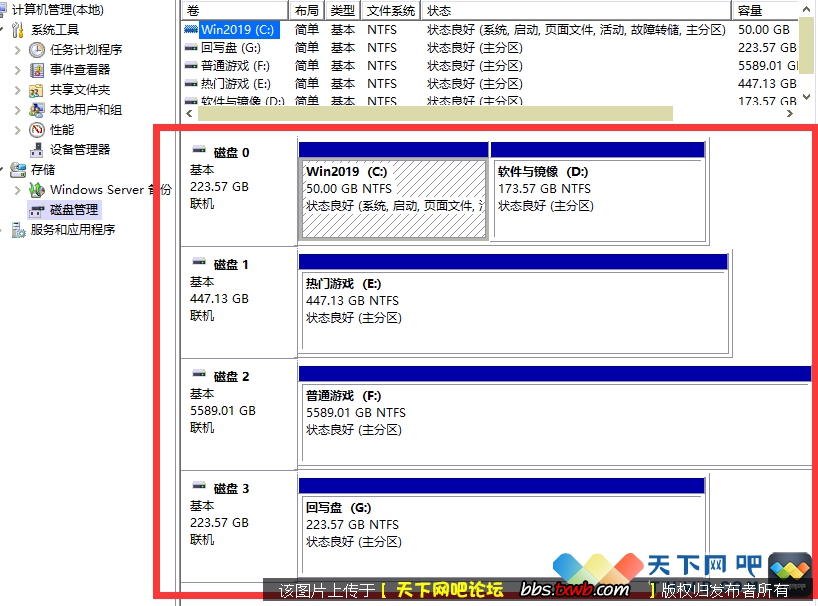
十年前发布的Conroe有如下五款产品:

旗舰产品X6800主频高达2.93Ghz,支持更高的前端总线频率,芯片面积143平方毫米,比前代Pentium D的162平方毫米更小,由于不集成GPU,十年前的处理器比今天的产品小得多。
当年X6800的价格为999美元,跟今天8核的Core i7-5960X相当,而E6400则为224美元,和Core i5-6600一致,有意思的是,不知道是不是为了快点跟昨天说再见,intel把昨天还是次旗舰产品的3.4Ghz的Pentium D 945砍到比E6300还低的163美元,这是intel桌面处理器历史上独一无二的事件。
一切尽在预取(Prefetch)
CPU执行的指令来自译码器,数据取自高速缓存(Cache),在理想环境中,数据和指令都可以从底层缓存中获取(一级缓存,L1 Cache),延迟极低,不存在瓶颈。现实环境可没那么乐观,延迟完全靠猜,核心预测所需数据并且在用到它们之前放入底层缓存的能力决定了现实环境的延迟,这项技术就是预取。
酷睿2微架构增加了多重预取,这是过去在消费级处理器中从没出现过的,并且改进了预取算法,每个核心有两个数据和一个指令预取,加上二级缓存的两个预取,在双核酷睿2中总共有8个预取来维持处理器高效执行。
另一方面,预取还是为缓存索引做查找标签,数据预取这么做是为了避免程序运行的时候出现高延迟,数据预取是通过存储端口(store port)进行缓存索引,因为原则上载入操作(Load)的频度是存储操作(Store)的两倍,intel在酷睿2中巧妙的把存储端口这一相对空闲给利用起来。
缓存,多多益善离开了低延迟数据和指令存取,快速核心将会一文不值,所以最贵的SRAM作为一级缓存被用在离执行单元最近的位置,这里寸土寸金,限制了一级缓存的容量,所以CPU中的高速缓存都被设计成嵌套的结构,容量大得多的二级缓存(L2 Cache)被放在外围,一级缓存不命中(Cache Miss)就得到二级缓存甚至内存中查找数据,这些操作会带来延迟,影响执行速度。因此,缓存容量,多多益善,酷睿2拥有比前代产品以及竞争对手都要多的缓存。
酷睿2的缓存设计较前代Pentium4的变化体现在一级缓存大幅增加到32KB,,延迟降低到3个时钟周期,二级缓存则为双核共享的4MB,延迟降低到12~14时钟周期。对手AMD的K8虽然有更大容量的一级缓存,内置内存控制器的设计相比Pentium4有较大优势,但带宽偏小,二级缓存容量也有明显差距,实测表明,酷睿2一级缓存带宽为K8的2倍,二级缓存则达到2.5倍。
译码,四发射与融合译码器的作用是对指令进行解码,并且将这些长度为1~15字节不等的指令翻译成类RISC的定长指令便于执行,在酷睿2中,称之为微操作(micro-op)。预取配合译码是当代X86处理器设计的核心,酷睿2中有四组译码器,其中三组为简单译码器,一组是复杂译码器,前者能将指令翻译成一条微操作,功耗更低晶体管更少,而后者则可以转换出四条(长指令的利器)。这就是俗称的四发射,酷睿2是X86桌面处理器中引领了四发射的潮流。
此外,酷睿2加入了宏操作融合(Macro-op Fusion),这样两条常规X86指令(或者宏操作)会被同时译码以增加并发,同时允许一条微指令包含两条计算机指令,这使得四个译码器单周期最多可以解析5条指令,相当于增加了译码带宽,这样也降低了乱序执行(OoO)所需要的缓冲大小。在当时,经典的X86程序,20%的宏操作可以被这样融合,由此可以带来11%的性能提升。
另一项特别的技术是指令直接跟内存地址融合,在经典的RISC规范中,需要添加寄存器查找内存地址的指令,所以传统上要用到3条微操作:


本文来源:不详 作者:佚名

 天下网吧・网吧天下
天下网吧・网吧天下