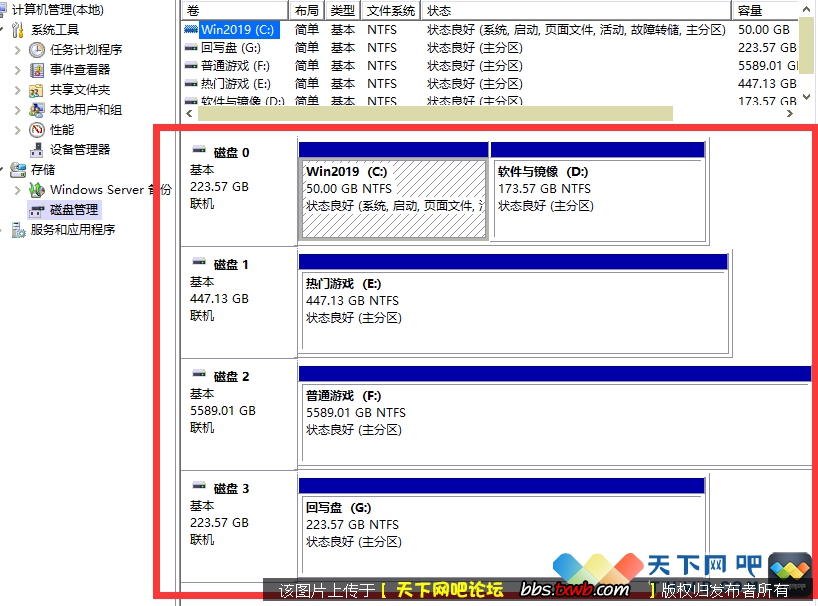
ФЧаЉЫЕЙШИшЗвыШУзЈвЕЗвыЖЊЗЙЭыЕФШЫЃЌПЯЖЈУЛгУЙ§
ЧыИїЮЛЧзАЎЕФЖСепХѓгбМЧЕУЃЌЫљгаУЛгаИјГіЪБМфЦкЯоЕФПЦММдЄВтФЧЖМЪЧдкЫЃСїУЅЁЃ
ЕБвЛПюаТЕФММЪѕЃЌВЛЃЌгІИУЫЕЕБвЛИіММЪѕГіЯжСЫвЛЖЁЕуаРЯВЕФНјВНЪБЃЌЯждкПЦММШІРяОЭСЂПЬЭљЫќЕФЩэЩЯЬљЩЯИїжжЁАЕпИВЁБЕФБъЧЉЁЃ
ШчЙћФуЪЧвЛЮЛПЦММаТЮХЕФЖСепЃЌЯыБивбОЖдЁАЕпИВЁБетИізжблИаЕНаЉаэЕФТщФОЩѕжСЖёаФСЫАЩЃПФЧЬьЗЕиИВЕФБфЛЏЫЦКѕОЭвЊГіЯждкУїЬьЁЃ
ПЦММУНЬхЩЦгкЮќв§ШЫУЧФПЙтЃЌетЙЬШЛЪЧДгвЕШЫдБЕФвЛжжБиБИБОСьЃЌЕЋШчНёЫљгаШЫЖМзѓЙЫгвХЮЃЌЯёЪЧШШЙјЩЯЕФТьвЯвЛбљНЙдъВЛАВЃЌетецЕФЪЧе§ГЃЯжЯѓТ№ЃППЦММУНЬхблжаЁЃПЦММДДаТАбЪРНчЪРНчНСЕФЬьЗЕиИВЁЃУЛЪТЖљШ§ЬьвЛДДаТЃЌЮхЬьвЛЕпИВЃЌЮДРДЮвУЧдкетИіЪРНчеОЮШНХИњЕФзХСІЕугжЪЧдкФФРяФиЃП
дкетЦфжаЃЌгШЦфЪЧвдЮЇШЦзХЁАШЫЙЄжЧФмЁБЕФКєЩљзюЮЊакгПХьХШЁЃЧАВЛОУЃЌGoogleЭЦГіСЫЛљгкЩёОЭјТчЖјПЊЗЂЕФШЋаТЕФGoogle TranslateЃЌв§Ц№вЕНчЕФвЛЦЌОЊКєЁЃВЛЩйШЫЩѕжСЖМНЈвщЙњМвЭъШЋУЛгаБивЊдкПЊЩшЭтгязЈвЕСЫЃЌЗвыОЭДЫдкЛњЦїбЇЯАЕФДјЖЏЯТГЙЕзЯћЪЇСЫЃЁ
ШЛЖјЪТЪЕЩЯЃЌШчЙћЮвУЧеОЕФдЖвЛаЉШЅПДЫќЃЌШчЙћЛЙФЃК§ВЛЧхОЭдйдкЖюЭЗЩЯЬљИіБљПщЖљЃЌФуОЭЛсЗЂЯжШЮКЮгаЙиЁАЛњЦїНЋШЁДњШЫЙЄЗвыЁБЕФбдТлЖМЪЧЮоЛќжЎЬИЁЃНёЬьЃЌЮхЪЎЖШЙшЛсКУКУЕиИњДѓМвъўГЖъўГЖЮЊЪВУДЛњЦїДњЬцВЛСЫШЫЙЄЕФЗвыЃЌВЂгЩДЫЮвУЧПЩвдЩдЮЂСФвЛСФШЫгыЛњЦїОПОЙгІИУБЃГжетбљЕФвЛжжЙиЯЕЁЃ

GoogleЕФЩёОЭјТчЗвыОПОЙЪЧдѕУДвЛЛиЪТЃП
ЪТЪЕЩЯЃЌЪЎФъжЎЧАЭјТчЩЯОЭвбОЬсЙЉдкЯпЗвыЗўЮёСЫЃЌЖјЦфЪЕдкКмдчвдЧАЃЌЙигкЁАЛњЦїМДНЋЬцДњШЫРрНјааЗвыЁБЕФТлЕїОЭВЛОјгкЖњЁЃЖјжЎЫљвдШчНёДѓМвЕФФПЙтдйДЮЛиЕНетЩЯУцЃЌЭъШЋЪЧвђЮЊGoogleНЋздМКЕФдкЯпЗвыЗўЮёНјааСЫЩ§МЖЛЛДњЃЌЭЦГіСЫвЛПюУћЮЊЛљгкЁАЩёОЭјТчЁБЕФЛњЦїЗвыЯЕЭГЁЃ
длУЧЯШЫЕЫЕЪВУДЪЧЁАЩёОЭјТчЁБЃП
здДђгаСЫМЦЫуЛњвдРДЃЌХЌСІШУЛњЦїжЧФмж№НЅЯђШЫРрДѓФдЙ§ЖЩГЩЮЊСЫКмЖрПЦбаШЫдБЕФвЛИіУЮЯыЁЃЕЋжБЕНШчНёЃЌдкетЗНУцЕФНјеЙМИКѕПЩвдгУЮЦЫПВЛЖЏРДаЮШнЁЃШЫУЧЖМЧхГўЃЌЛњЦїКЭШЫРрЕФВржиЕуВЛвЛбљЁЃдкЛњЦїблжаВЛЗбДЕЛвжЎСІЕФдЫЫуЃЌТпМХаЖЯЃЌетдкШЫРрРДПДЪЧашвЊДѓСПФдСІВХФмЭъГЩЕФЪТЃЌЖјЖдгкШЫРрРДЫЕЃЌФЧаЉЧсЖјвзОйОЭФмАьЕНЕФЪТЃЌБШШчБцЪЖЮяЬхЃЌШЫУЧЕФЩэЗнЃЌздгЩСїГЉЕФгябдЙЕЭЈЃЌбИЫйЕибЇЯАВЂЪЪгІФГвЛжжЗНбдЃЌетаЉЖдгкЛњЦїРДЫЕМђжБЪЧВЛПЩФмЭъГЩЕФШЮЮёЁЃ
дкКУМИДЮЯђЁАШЫФдЁБЗЂЦ№ГхЗцЮДЙћжЎКѓЃЌбаОПШЫдБЬсГіЩшЯыЃЌЮЊЪВУДЮвУЧВЛДюНЈвЛИіРрЫЦгкШЫФдвЛбљЕФЩёОЭјТчФиЃПШУМЦЫуЛњдЫЫуЕЅЮЛжЎМфЕФЙиЯЕДюНЈЃЌОЭЭъШЋАДееШЫФдРДЩшМЦЁЃЫфШЛЃЌ
ШЫРржСНёЩаЮДУїАзШЫФдЕФЙЄзїдРэЃЌВЛЙ§етУЛЙиЯЕЃЌЮвУЧПЩвдЯШИДжЦГівЛИіШЫФдЕФМЦЫуФЃаЭЃКвЛМўЪТЧщВЂЗЧЯёМЦЫуЛњГЬађФЧбљЪфШыжИСюЪфГіНсЙћЃЌЖјЪЧдкШЫФдЕФЖрИіЩёОдЊДЋЕнЃЌУПИіЩёОдЊЖМЖдаХЯЂНјааздМКЕФМгЙЄЃЌзюКѓЪфГіЕФНсЙћЁЃМЦЫуЛњПЦбЇМвгУЭЌбљЕФЗНЪНЃЌдкЪфШыКЭЪфГіжЎМфЃЌМгШыСЫЗЧГЃЖрЕФЁАНкЕуЁБЃЌУПИіНкЕуЛсЖдЧАвЛИіНкЕуДЋРДЕФЪ§ОнЃЌАДеездМКгЕгаЕФвЛИіШЈжиЯЕЪ§НјааМгЙЄЃЌгаЪБКђНкЕуЛЙЛсЗжВуЁЃетОЭЪЧЁАШЫЙЄЩёОЭјТчЁБЃЈArtificial Neural NetworksЃЌANNЃЉЁЃ
ФЧУДЃЌGoogleИуЕУетДЮЛљгкЩёОЭјТчЕФЛњЦїЗвыЯЕЭГгжЪЧдѕУДвЛЛиЪТФиЃП
жЎЧАЮвУЧОГЃгУЕНЕФЗвыЗўЮёЃЌЦфЪЕЪЧЛљгкЁАДЪзщЁБРДНјааЕФЁЃвВОЭЪЧЫЕЃЌвЛЖЮЮФзжГіЯжжЎКѓЃЌЯЕЭГЛсжБНгАбетЖЮЮФзжИјВ№ЩЂСЫЃЌзюаЁЕЅЮЛОЭЪЧЁАДЪзщЁБЃЌШЛКѓНЋУПИіДЪзщевЕНЯрЖдгІЕФЗвыАцБОЃЌдйНјааДЮађЕФЕїећЃЌзюКѓГіРДвЛЦЊвыЮФЁЃетЪЧвЛИігазХУїШЗЕФЯШКѓДЮађЕФЗвыЙЄзїЃЌМДЃКДђЩЂЁЂевЖдгІЕФДЪзщЁЂХХађЁЂЦфжаАќРЈСЫБъЕуЗћКХЕФжиаТЗжИюЃЌећРэЕШЖрИіЛЗНкЁЃ
АДЕРРэРДЫЕЫќЦфЪЕВЛдѕУДШнвзГіДэЃЌЕЋЪЧУПвЛИіЛЗНкЫфШЛзМШЗТЪЛЙТљИпЃЌЕЋЪЧМмВЛзЁЛЗНкЖрАЁЃЌвЛЕЉгавЛИіЕиЗНГіЯжСЫЦЋВюЃЌКѓУцОЭШчЕЙЕєЕФЛ§ФОвЛбљШЋВПЖМЩЂСЫМмСЫЃЌзюКѓГіРДЕФЗвыФкШнЕБШЛВЛШЬтЇЖСЁЃ
ЖјЛљгкЩёОЭјТчЕФЗвыЯЕЭГЃЌжБНгЬјЙ§СЫетУДЖрЗБЫіЕФВНжшЃЌЫќжБНгжБНгвРППЁАКЃСПЪ§ОнЁБРДЛёЪЄЃЌвВОЭЪЧЫЕЫќжБНгНЈСЂЦ№РДСЫСНИіЖдгІзХЕФЦНаагябдПтЃЌШЛКѓШУЛњЦїздМКШЅбЇЯАШчКЮНјааЖдгІЁЃетбљЕФЗЈзгЦфЪЕКмдчОЭГіЯжСЫЃЌЕЋЪЧЫќвВгавЛЖЈЕФММЪѕФбЬтУЛгаЙЅЦЦЃЌБШШчЫЕЛњЦїбЇЯАЦ№РДЫйЖШЪЕдкЗЧГЃТ§ЃЌЖјЧвЩдЮЂХіЩЯвЛаЉУЛдѕУДМћЙ§ЕФЛАЃЌЫќОЭВЛжЊЕРИУдѕУДАьСЫЃЌЕЋЪЧGoogleетДЮЭЈЙ§ММЪѕДДаТЃЌШУЫќЮоТлдкЗвыЕФзМШЗадКЭЫйЖШЩЯЖМЛёЕУСЫДѓДѓЕФЬсЩ§ЁЃ
гЩДЫЃЌЗвыдйвВВЛЪЧМђЕЅЕФДЪгыДЪЃЌДЪзщгыДЪзщЕФЖдгІЃЌЖјЪЧФмЙЛДгвЛЖЮЮФеТЕФНЧЖШШЅАбЮеШЋЮФЃЌетбљГіРДЕФвыЮФИќМгСїГЉздШЛЁЃ
ФЧУДЃЌетЪЧВЛЪЧОЭвтЮЖзХШЫРрЗвыдкДЫЯТИкСЫФиЃП
МШШЛЮвУЧЯждкжЊЕРСЫGoogleЗвыдкДЫШЁЕУЕФжиДѓНјеЙЃЌФЧУДЯждкЪЧЪБКђАбЛњЦїКЭШЫРрЗХдкЗвыЕФЬьЦНЩЯГЦГЦНяСНЃЌБШНЯвЛЯТЪыЧсЪыжиСЫЃЁ
ЪзЯШЕквЛЕуЃКЗвыЪЧвЛМўЗЧГЃРЇФбЕФЙЄзїЃЌгааЉЗвыЩѕжСЪЧМЋОпЗвыВХЛЊЕФШЫЖМЮоЗЈЪЄШЮЁЃ
ЛњЦїжЎЫљвдЮоЗЈШЁДњзЈвЕвыдБЃЌЦфЪЕЕРРэКмМђЕЅЃКЯждкдкЙњЭтЩњЛюЃЌФмЙЛздгЩЪЙгУСНЙњгябдЕФШЫФЧУДЖрЃЌЕЋВЂВЛвтЮЖзХЫћУЧОЭФмЬсЙЉзЈвЕЕФЗвыЗўЮёЁЃ
ЖдгкКмЖрЗвыЙЄзїРДЫЕЃЌЗвыЫљвЊЧѓЕФВЂВЛНіНіЪЧФуашвЊЪьЯЄСНЙњЙњМвЕФгябдЮФзжЁЃКмЖрШЫОѕЕУЗвыЮоЗЧОЭЪЧНЋСНжжгябдзжЖдзжЃЌДЪЖдДЪЃЌОфЖдОфЕФЖдгІЦ№РДЃЌЦфЪЕВЂЗЧШчДЫЁЃвыдБвВВЛЪЧвЛБОЛсаазпЕФЁАЛюзжЕфЁБЁЃ
ИќзМШЗЕФЫЕЃЌЫћУЧЪЧСНжжЮФЛЏжЎМфЕФЧХСКЃЌдкЫћУЧДѓФдЖдаХЯЂЕФЯћЛЏЁЂМгЙЄЁЂЙ§ТЫжЎКѓЃЌгябдВЛНіНіЪЧДгаЮЪНЩЯБфЕУЪьЯЄЃЌЖјдкЮФЛЏЩЯУцвВОЁПЩФмЕиЬљНќЁЃгааЉЪБКђЃЌЫћУЧЩѕжСЛсЗЂУїДДдьвЛаЉЫЕЗЈЃЌЪЙЕУШЫУЧИќШнвзНгЪмЃЌгааЉвыдБгаПЩФмЧуЦфвЛЩњЃЌНЋдкСНИіВЛЭЌЕФЙњМвЕФЩњЛюОбщЙрзЂЕНЗвыЙЄзїжаЃЌЪЙЕУСНжжЮФЛЏФмЙЛИќКУЕФНЛШкЁЃЖјЛњЦїЃЌЪЧЮоЗЈзіЕНетвЛаЉЕФЁЃ
2ЁЂЗвыжЪСПУЛгаЕЅвЛБъзМЁЃ
ОЭЫуЪЧЛњЦїЭЈЙ§СЫЩЯУцетвЛЕРЙиПЈЕФПМбщЃЌФмЙЛЧсЫЩГаЕЃЦ№ИїЯюЗвыЙЄзїЃЌЕЋЪЧЫќЕФЗвыжЪСПЪЧЗёгавЛИіБъзМНјааКтСПФиЃПЯдШЛЪЧУЛгаЕФЁЃФуНЋвЛЖЮЮФБОНЛИј100ИіШЫРрвыдБЃЌЫћУЧЛсИјФувЛАйжжВЛЭЌЕФАцБОЃЌФФжжЗвыжЪСПИпЃПФФжжЕЭЃПгаЕФвВаэдкааЮФдьОфЩЯМЋЮЊгХУРСїГЉЃЌгаЕФдђЪЧдкТпМТлжЄЩЯУцЪЎЗжЕФбЯНїе§ЪНЃЌдкУцЖдВЛЭЌЕФЖдЯѓЃЌВЛЭЌЕФЛЗОГЪБЃЌПМСПЕФБъзМЪЧВЛвЛбљЕФЁЃЖјШЫгыШЫжЎМфЕФНЛСїаЇЙћЃЌЪЧЮоЗЈЭЈЙ§ЛњЦїРДЪЕЯжЕЅвЛБъзМЛЎЖЈЕФЁЃ
ЫќВЂВЛЪЧвЛГЁЯѓЦхБШШќЃЌгЕгаЗЧГЃПЭЙлЕФТпМЭЦРэЁЃжЎЫљвдгаЖрИіЗвыАцБОЃЌгАЯьвђЫиГ§СЫгяЗЈЩЯЕФПМСПЃЌЛЙгагябдЩювтЕФВржиЕуЃЌФФХТЪЧЭЌбљвЛОфЛАЃЌдкВЛЭЌЕФШЫФЧРяЖСЦ№РДЃЌвђЮЊгяЕїЁЂгяЦјЕШдвђЃЌвВЛсГЪЯжЮЂУюЕФЧјБ№ЁЃ
3ЁЂЪРНчЩЯЕФгябджжРрЬЋЖрСЫЃЌдЖГЌЙ§ФуЕФЯыЯѓЁЃ
ЯждкЕФGoogle TranslatжЇГжЗвы80жжгябдЃЌЕЋЪЧШчНёдкЮвУЧЕФЪРНчЩЯЃЌЛЙДцдкзХ6000ЕН7000жжгябдЃЌЦфжа2000жжЫфШЛБєСйУ№ОјЃЌЕЋЮвУЧОЭЫуЪЧФУБЃЪиЙРМЦРДЫуЃЌетЦфжага1000жжгябддкОМУВуУцОпгаживЊгАЯьСІЃЌФЧУДGoogleМДЛЙЕУШЅеїЗў920жжгябдЃЌОЭЫуЪЧУПФъGoogleЕФЗвыФмСІРЉеХ10жжгябдЃЌФЧУД92ФъжЎКѓЃЌGoogleЗвыВХЫуЪЧУуЧПИВИЧСЫШЫРрЕФгябдЭМЦзЁЃ
4ЁЂгяОГЪЧЙиМќЁЃ
ОЭФУгЂгяРДОйР§згКУСЫЃЌМИКѕУЛШЫжЊЕРЃЌвЛИіЕЅвЛЕФДЪЛуЛсгаМИАйжжЕФвтЫМЃЌетЭъШЋШЁОігкЕБЪБЫЕЛАЕФгяОГЪЧЪВУДЁЃЪТЪЕЩЯЃЌХЃНђгЂгяДЪЕфжаЙтЪЧЁАRunЁБетвЛИіЕЅДЪЃЌОЭжСЩйга645жжВЛЭЌЕФвтЫМЁЃвЛЬЈЕчФдецЕФВЛНіНіФмдквЛжжгябджаЪЖБ№етУДЖрЕФвтЫМЃЌЖјЧвЛЙФмдкСНжжгябджаевЕНвЛвЛЖдгІЙиЯЕТ№ЃП
ЛЛОфЛАЫЕЃЌДЪгыДЪЖдгІЕФЗвыЪЧВЛЯжЪЕЕФЃЌеце§ЕФЗвыВЛЪЧДгЁАзжДЪЁБШЅзХблЃЌЖјЪЧНЋЁАгяОГЁБКЭЁАвтвхЁБСНепНсКЯЦ№РДЁЃЖјетСНепНсКЯЦ№РДЕФЗНЪНЛЙдкВЛЖЯЕиЗЂЩњзХБфЛЏЃЌетжжБфЛЏБГКѓЕФЖЏвђЃЌдђЪЧРД


БОЮФРДдДЃКВЛЯъ зїепЃКи§Ућ

 ЬьЯТЭјАЩЁЄЭјАЩЬьЯТ
ЬьЯТЭјАЩЁЄЭјАЩЬьЯТ